La empresa china Moonshot AI ha anunciado el lanzamiento de Kimi K2 Thinking, un modelo de inteligencia artificial de código abierto que ha alcanzado resultados superiores a los de modelos cerrados punteros, como GPT-5 de OpenAI y Claude Sonnet 4.5 de Anthropic, en múltiples benchmarks.
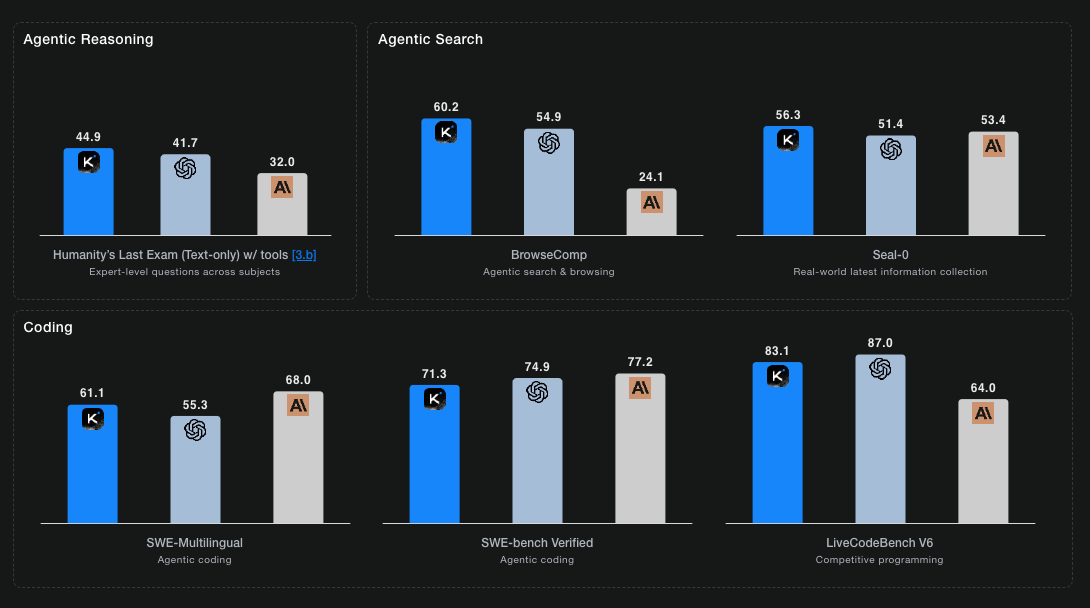
En concreto, en el test Humanity’s Last Exam, K2 Thinking logró un 44,9 % de acierto, superando a esos modelos cerrados. Esta noticia resulta muy relevante para despachos profesionales, asesorías y despachos de innovación, por dos razones fundamentales:
- Señala que los modelos de IA avanzados ya no están únicamente en manos de grandes proveedores cerrados, lo cual abre nuevas oportunidades de personalización, licenciamiento o integración para pymes y firmas de servicios. [Smart cope]
- Invita a reflexionar sobre el impacto operativo: qué necesitarían las asesorías tecnológicas para incorporar este tipo de modelos, qué barreras existen (infraestructura, costes, licencia) y cómo pueden posicionarse en este nuevo contexto. [Binar y Verseai]
Cómo funciona K2 Thinking: tecnología, agente y eficiencia
Arquitectura y capacidades destacadas
- Kimi K2 Thinking emplea una arquitectura de Mixture of Experts (MoE) con un total de aproximadamente un billón de parámetros, aunque activa unos 32 mil millones de parámetros por inferencia.
- Soporta una ventana de contexto muy amplia, hasta 256.000 tokens en algunos casos, lo que le permite procesar cadenas largas de razonamiento.
- Incorpora de forma nativa el llamado “razonamiento + herramientas”: es decir, el modelo puede realizar llamadas a herramientas externas (buscadores web, ejecución de código, APIs) durante su proceso de razonamiento, algo que hasta ahora era exclusivo de modelos premium cerrados. [Cyber news]
Rendimiento y coste operativo
- En la prueba Humanity’s Last Exam obtuvo 44,9 % de acierto.
- En la prueba BrowseComp (evaluación de razonamiento a través de herramientas de navegación web) alcanzó 60,2 %.
- Según análisis técnicos, su coste de entrenamiento habría sido de apenas unos 4,6 millones de dólares, muy inferior al coste estimado de los grandes modelos anteriores.
Las barreras siguen siendo importantes
- Aunque “open-weights”, su uso local exige una infraestructura muy exigente: se menciona la necesidad de 8 unidades gráficas NVIDIA H200 (o equivalente) y alrededor de 1 TB de VRAM.
- En otros análisis se advierte que “open source” no significa “barato de desplegar”: aunque la licencia es abierta, las condiciones de infraestructura (y competencias técnicas) limitan todavía su uso generalizado.
Retos y elementos críticos a considerar
- Licencia y cumplimiento: Aunque el modelo es open-weights, conviene revisar los términos de uso (especialmente para explotación comercial) y la gestión de datos sensibles en el contexto de despachos profesionales (confidencialidad, protección de datos).
- Infraestructura y coste operativo: Como se apuntaba, la ejecución local es cara. Puede ser más sensato usar APIs o plataformas gestionadas.
- Capacitación y cambio cultural: Los clientes pymes o las propias asesorías tendrán que adaptarse a una lógica de IA de razonamiento, no solo de respuestas. Esto implica definir los casos de uso, gestionar expectativas y asegurar calidad y trazabilidad.
- Integración con procesos existentes: No basta con “instalar” el modelo: hay que integrarlo en flujos de trabajo, definir qué datos usar, cómo gestionar resultados, cómo supervisar.
- Ética y gobernanza: Un modelo con capacidad de usar herramientas y razonar plantea preguntas sobre transparencia, explicabilidad, errores, responsabilidad. Los despachos deben estar preparados para asesorar en estos aspectos.






